日常生活のあらゆる場面で目にするQRコード。スマートフォンをかざせば瞬時に情報にアクセスできる便利なツールですが、世界中で無数に使われているにもかかわらず、なぜコードが重複しないのか不思議に思ったことはありませんか?
QRコードの組み合わせパターンは実質的に無限に近い数が存在します。この圧倒的な数の多様性こそが、世界中で同時に使用されても衝突しない理由なのです。
バーコードの進化形として登場したQRコードは、従来の一次元バーコードと比較して格段に多くの情報を格納できるようになりました。その背景には、緻密に設計された数学的な仕組みと、膨大な組み合わせの可能性が隠されています。
本記事では、QRコードが一体何通り存在するのか、そしてなぜ重複が起こらないのかについて、具体的な数字と仕組みを交えながら詳しく解説していきます。QRコードの秘密を知ることで、この小さな四角いパターンへの見方が変わるかもしれません。
QRコードの基本構造と情報量の関係
それではまず、QRコードの基本的な構造と、そこに格納できる情報量について解説していきます。
QRコードのバージョンとサイズ展開
QRコードには「バージョン」という概念が存在し、バージョン1からバージョン40まで、計40種類の規格があります。バージョンが上がるごとにコードのサイズが大きくなり、格納できる情報量も増加するのです。
バージョン1は21×21のセル(モジュール)で構成され、最も小さいQRコードとなります。そこから4セルずつ増えていき、バージョン40では177×177という巨大なサイズに到達するでしょう。
【バージョンとサイズの計算式】
セル数 = 21 + (バージョン番号 – 1) × 4
例: バージョン10の場合
21 + (10 – 1) × 4 = 21 + 36 = 57セル
この規格の多様性により、少量のテキストから大容量のデータまで、用途に応じた最適なQRコードを生成できます。
エラー訂正レベルと情報格納容量
QRコードには4段階のエラー訂正レベルが設定されています。L(約7%)、M(約15%)、Q(約25%)、H(約30%)という段階があり、数字が大きいほど破損に強くなる一方で、格納できるデータ量は減少するのです。
エラー訂正機能は「リードソロモン符号」という高度な数学的手法を用いており、コードの一部が汚れたり欠けたりしても正確に読み取れるように設計されています。
| エラー訂正レベル | 復元可能率 | 用途例 |
|---|---|---|
| L (Low) | 約7% | クリーンな環境での使用 |
| M (Medium) | 約15% | 一般的な用途 |
| Q (Quartile) | 約25% | 工場など汚れやすい環境 |
| H (High) | 約30% | 長期保存や屋外使用 |
このエラー訂正機能があるからこそ、QRコードは実用的なツールとして広く普及したと言えるでしょう。
データ種別による格納可能文字数
QRコードに格納できるデータ量は、数字、英数字、バイナリ、漢字といったデータの種類によって異なります。最も効率的なのは数字のみのデータで、バージョン40・エラー訂正レベルLの場合、最大7,089文字もの数字を格納可能です。
英数字では最大4,296文字、バイナリ(8ビット)では2,953バイト、漢字では1,817文字まで格納できます。この多様性により、URLから連絡先情報、WiFi設定まで幅広い用途に対応できるのです。
データの種類によって圧縮効率が変わるため、同じバージョンのQRコードでも実際に入る情報量は大きく変動します。効率的なQRコード生成には、データ特性の理解が不可欠でしょう。
QRコードの組み合わせは実際に何通り存在するのか
続いては、QRコードの組み合わせパターンが具体的に何通り存在するのかを確認していきます。
最小構成での理論的組み合わせ計算
最もシンプルなバージョン1のQRコードでも、理論上の組み合わせは天文学的な数字になります。21×21=441個のセルがあり、各セルは白か黒の2通りの状態を取るため、2の441乗という膨大な組み合わせが理論的には存在するのです。
【バージョン1の理論的組み合わせ】
2^441 ≒ 9.04 × 10^132通り
これは1の後に132個のゼロが並ぶ数字!
ただし実際には、位置検出パターンやタイミングパターンなど固定部分が存在するため、すべてが自由に変更できるわけではありません。それでも残る可変部分だけで、実用上無限と言える組み合わせが生まれます。
この数字は宇宙に存在する原子の総数(約10^80個)をはるかに超える規模。まさに天文学的というにふさわしい数値でしょう。
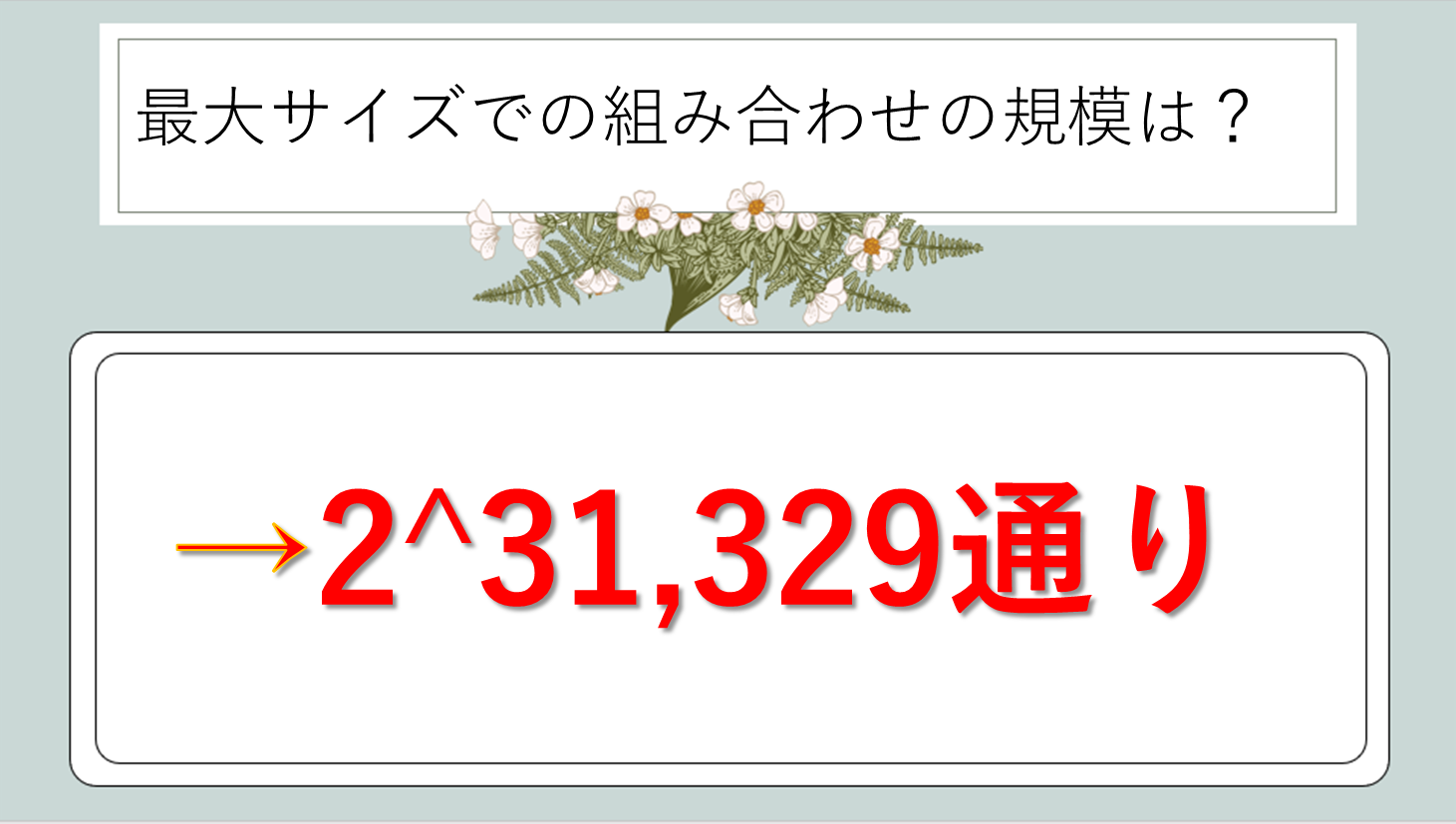
バージョン40での組み合わせの規模
最大サイズのバージョン40になると、組み合わせの数はさらに想像を絶するレベルに達します。177×177=31,329個のセルが存在し、固定パターンを除いても実質的に無限大と表現するしかない組み合わせ数が生まれるのです。
仮に全セルが自由だとすれば2^31,329通りとなり、これは10^9,430程度の数字。数学的表記でしか表現できない領域です。
バージョン40のQRコードの組み合わせは、既知の宇宙全体の原子数を何乗しても足りないほどの規模であり、人類が生み出すすべてのQRコードが重複する確率は実質ゼロに等しい。
この圧倒的な組み合わせの多様性が、QRコードが世界標準として機能する数学的基盤となっています。
実用レベルでの重複確率の検証
理論的な組み合わせ数と実際の使用状況を比較すると、重複の可能性は限りなくゼロに近いことが分かります。世界中で毎日数億個のQRコードが生成されていると仮定しても、組み合わせの総数に対する使用率は無視できるレベルなのです。
たとえば1秒間に100万個のQRコードを生成し続けたとしても、バージョン10程度の組み合わせをすべて使い切るには、宇宙の年齢(約138億年)をはるかに超える時間が必要でしょう。
実際には、同じデータを入力すれば同じQRコードが生成されますが、URLやID、タイムスタンプなどユニークな要素を含むことで、自然と重複が避けられる仕組みになっています。
QRコードが被らない仕組みとデザインの秘密
続いては、QRコードが実際に重複しない理由と、その技術的な仕組みを確認していきます。
データエンコード方式による一意性の確保
QRコードは入力されたデータを数学的なアルゴリズムでエンコードするため、同じデータからは常に同じパターンが生成されるという特性があります。逆に言えば、データが1文字でも異なれば、まったく別のパターンになるのです。
このエンコード過程では、データをビット列に変換し、モードインジケータやデータ長、誤り訂正コードなどを付加します。これらすべての要素が組み合わさって最終的なパターンが決定されるため、偶然の一致は実質的に起こりえません。
データに日時やランダムな識別子を含めることで、さらに確実に一意性を保証できます。多くのQRコード生成システムでは、タイムスタンプやシリアル番号が自動的に付与される仕組みを採用しているでしょう。
マスクパターンによる最適化処理
QRコードには8種類のマスクパターンが用意されており、生成時に最も読み取りやすいパターンが自動選択されます。このマスク処理により、白黒のバランスや連続パターンの偏りが最適化されるのです。
| マスク番号 | パターン条件 | 効果 |
|---|---|---|
| 000 | (i + j) mod 2 = 0 | チェッカーパターン |
| 001 | i mod 2 = 0 | 水平ストライプ |
| 010 | j mod 3 = 0 | 垂直ストライプ |
| 011 | (i + j) mod 3 = 0 | 斜めパターン |
| 100-111 | その他複雑な条件 | 様々な最適化 |
同じデータでもマスクパターンによって見た目は変わりますが、読み取り結果は同一です。この技術により、読み取り精度が大幅に向上しています。
位置検出パターンと形式情報の役割
QRコードの三隅にある特徴的な四角いマーク(ファインダーパターン)は、コードの向きや位置を瞬時に認識するための重要な要素。これにより360度どの角度からでも正確に読み取れるのです。
さらにアライメントパターン、タイミングパターン、フォーマット情報など、決められた位置に配置される固定要素があります。これらは「オーバーヘッド」として扱われ、実際のデータ領域とは明確に区別されるでしょう。
この構造化された設計により、読み取り装置は瞬時にQRコードを認識し、正確にデータを抽出できます。バーコードと比較して圧倒的に高速かつ確実な読み取りが可能になった理由がここにあるのです。
従来のバーコードとQRコードの決定的な違い
続いては、一次元バーコードとQRコードの本質的な違いを確認していきます。
一次元バーコードの限界と特性
従来のバーコード(JANコードやCODE39など)は、縦の線の太さと間隔で情報を表現する一次元の仕組みです。格納できる情報は通常20文字程度が限界で、主に商品コードや管理番号といった短い識別情報に使われてきました。
一次元バーコードは構造がシンプルなため読み取り装置も単純で済みますが、情報量の制約が大きな課題でした。URLや詳細な説明文を格納することは実質的に不可能だったのです。
また、バーコードは横方向にしか情報を持たないため、汚れや破損に弱いという弱点もあります。一部が読めなくなると全体が認識できなくなるリスクが常に存在しました。
二次元コードがもたらした革新性
QRコードは縦横両方向に情報を配置する二次元構造により、バーコードの数百倍から数千倍の情報を格納可能にしました。この飛躍的な容量増加が、QRコードの爆発的普及につながったのです。
JANコードが13桁の数字しか表現できないのに対し、QRコードは数千文字のテキストや複雑なURLを余裕で格納できる。この情報密度の違いが、使用用途の幅を決定的に広げた。
さらに前述のエラー訂正機能により、部分的な破損があっても読み取れる堅牢性を実現。屋外での使用や長期保存にも耐えられる信頼性を獲得しました。
スマートフォンの普及と相まって、QRコードは決済、チケット、認証など、生活のあらゆる場面で活用されるようになったのです。
データ密度と読み取り速度の比較分析
情報密度の観点では、QRコードは同じ面積に圧倒的に多くの情報を詰め込めます。バージョン1の小さなQRコードでも、最大300文字程度の英数字を格納可能で、これはバーコードの10倍以上です。
読み取り速度についても、QRコードは位置検出パターンにより瞬時に認識できるため、バーコードのスキャニング動作と比較して格段に高速。カメラで撮影するだけで完了する手軽さも魅力でしょう。
| 比較項目 | 一次元バーコード | QRコード |
|---|---|---|
| 最大文字数 | 約20文字 | 数千文字 |
| エラー訂正 | なし | 最大30%復元 |
| 読み取り方向 | 横方向のみ | 全方向対応 |
| 主な用途 | 商品管理 | URL、決済、認証など多様 |
この圧倒的な性能差により、QRコードは現代のデジタル社会に不可欠なインフラとなりました。
まとめ QRコードの組み合わせはなぜ被らない?【バーコード】
QRコードの組み合わせパターンは、最小のバージョン1でも10^132通り以上という天文学的な数字に達します。最大のバージョン40ではさらに桁違いの組み合わせが存在し、実質的に無限と言える多様性を持っているのです。
このため世界中で同時に無数のQRコードが使用されても、重複する確率は限りなくゼロに近い状況が実現されています。データエンコード方式やマスクパターン、エラー訂正機能など、緻密に設計された仕組みが一意性を保証しているのです。
従来のバーコードと比較して、情報格納量で数百倍、エラー耐性や読み取り速度でも圧倒的な優位性を持つQRコード。その普及の背景には、数学的な確かさと技術的な工夫が存在します。
日常的に使っているQRコードの小さな四角の中に、これほど深い技術と膨大な可能性が詰まっていることを知ると、見る目が変わってくるでしょう。今後もQRコードは進化を続け、私たちの生活をより便利にしてくれるはずです。