実験データや調査結果を分析するとき、「この差は本当に意味があるのか、それとも偶然なのか」を判断する指標として「p値」は欠かせません。
p値は統計検定の中心的な概念ですが、「難しそう」「専門的な統計ソフトが必要」と思われがちです。
実際には、エクセルの標準関数だけでt検定・z検定・F検定などのp値を求めることができます。
この記事では、エクセルでp値を求める方法(p値の出し方・計算式・統計検定での使い方)について、p値の基本概念から各検定に対応した関数の使い方・結果の解釈まで、イメージ図を交えながら丁寧に解説していきます。
統計の知識に自信がない方でも理解できるよう基礎から説明していますので、ぜひ最後までお読みください。
【結論】エクセルでp値を求めるにはT.TEST関数・NORM.S.DIST関数・CHISQ.TEST関数などを用途に合わせて使い分けるのが基本で、分析ツールを使えばより詳細な統計量とp値を一括出力できる
それではまず、エクセルでp値を求める方法の全体像と、検定の種類ごとに使うべき関数の結論について解説していきます。
p値とは、「帰無仮説が正しいと仮定したとき、今回観測された結果と同じかそれ以上に極端な結果が偶然起こる確率」のことです。
エクセルでp値を求める主な関数と検定の対応表
T.TEST関数 → 2群の平均値の差のt検定(対応あり・なし・等分散・不等分散)のp値を返す。最もよく使われる。
NORM.S.DIST関数 → z検定(正規分布)のp値を計算する際に使用。z値から確率を求める。
CHISQ.TEST関数 → カイ二乗検定のp値を返す。クロス集計表の独立性検定に使用。
F.TEST関数 → 2群の分散が等しいかどうかを検定するF検定のp値を返す。t検定の前処理として使用。
TDIST関数またはT.DIST関数 → t値と自由度からp値を直接計算する。t統計量がすでにわかっている場合に使用。
p値の判断基準として最もよく使われるのが「有意水準α=0.05(5%)」で、p値がこれより小さければ「有意差あり(統計的に意味のある差)」と判断します。
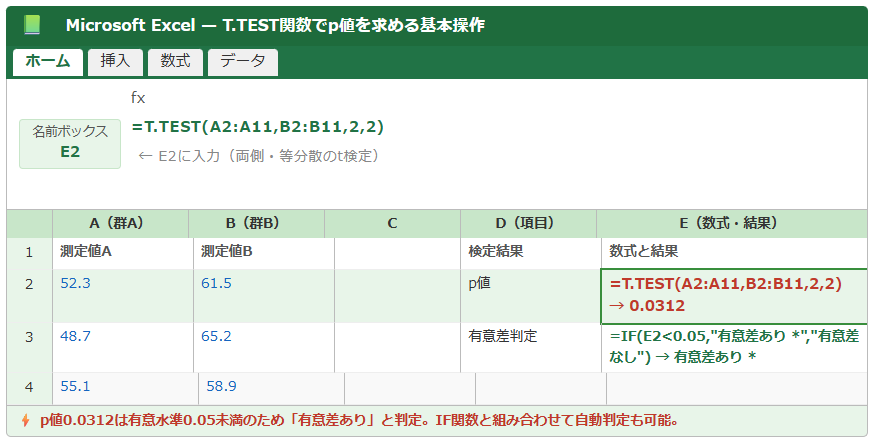
以下のイメージ図は、エクセルでT.TEST関数を使ってp値を求めている操作例を示しています。
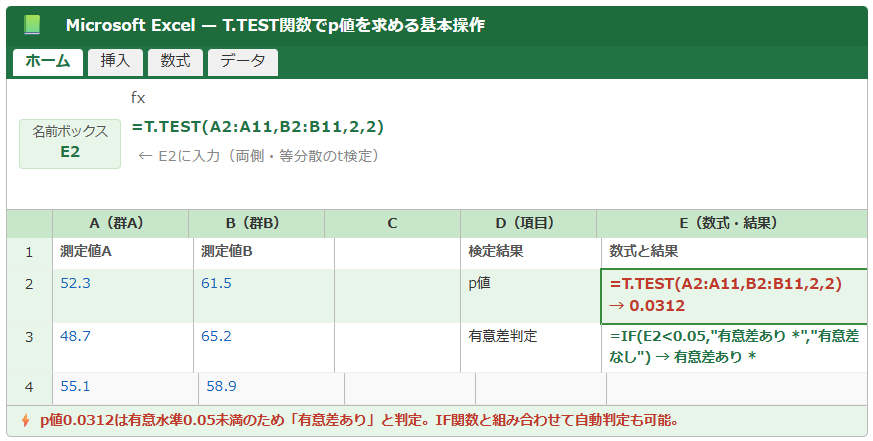
p値の基本概念と有意水準の意味
p値を正しく使いこなすためには、その意味をきちんと理解しておくことが大切です。
p値とは「帰無仮説(2群の間に差がないという仮定)が正しいと仮定したとき、今回と同じかそれ以上に極端なデータが得られる確率」のことです。
たとえばp値が0.03(3%)であれば、「もし本当に差がないなら、このような差が偶然起きる確率は3%に過ぎない」という意味になります。
この確率が非常に小さいほど、「偶然ではなく本当に差がある」と判断できます。
一般的に使われる有意水準(α)は0.05(5%)で、p値がαより小さければ「帰無仮説を棄却して有意差あり」と判断します。
p値の判断基準と表記方法
p値の解釈には慣習的な基準があります。
論文やレポートでは以下の表記が広く使われています。
p値の判断基準と表記の慣習
p値 ≥ 0.05 → 有意差なし(n.s. または ns と表記)
p値 < 0.05 → 5%水準で有意差あり(「*」と表記)
p値 < 0.01 → 1%水準で有意差あり(「**」と表記)
p値 < 0.001 → 0.1%水準で有意差あり(「***」と表記)
エクセルで自動判定する数式の例
=IF(E2<0.001,”***”,IF(E2<0.01,”**”,IF(E2<0.05,”*”,”ns”)))
→ p値に応じた星印を自動的に表示できる
p値の小ささは「効果の大きさ」を示すものではなく、あくまで「偶然性の低さ」を示します。
サンプルサイズが非常に大きい場合は実質的に意味のない小さな差でもp値が小さくなるため、p値とともに効果量(Cohen’s dなど)を報告することが近年では推奨されています。
エクセルでp値を扱う際に押さえるべき前提知識
エクセルでp値を計算する際には、使用する検定の種類を正しく選ぶことが最も重要です。
検定を誤って選ぶと、p値が正しく計算されても結論が誤ったものになります。
検定の選び方の基本的な判断基準は「比較する群の数」「データの対応の有無」「データの分布」の3点です。
2群の平均比較にはt検定、3群以上の比較にはANOVA(分散分析)、カテゴリデータの比較にはカイ二乗検定が一般的に使われます。
T.TEST関数・TDIST関数を使ってt検定のp値を求める方法
続いては、エクセルで最もよく使われる検定であるt検定のp値を、T.TEST関数とT.DIST関数を使って求める具体的な手順を確認していきます。
t検定は2群の平均値の差を比較する検定で、データが正規分布に従う場合に使用します。
T.TEST関数の書式と引数の詳細
T.TEST関数はt検定のp値を直接返す最も便利な関数です。
引数の意味を正しく理解することで、さまざまな種類のt検定に対応できます。
T.TEST関数の書式と引数の説明
=T.TEST(配列1, 配列2, 尾部, 検定の種類)
配列1 → 1つ目のデータ範囲(例 A2:A11)
配列2 → 2つ目のデータ範囲(例 B2:B11)
尾部 → 1(片側検定)または 2(両側検定)
検定の種類 → 1(対応のあるt検定)、2(対応なし等分散)、3(対応なし不等分散・Welch)
使用例(両側・Welch検定)
=T.TEST(A2:A11,B2:B11,2,3)
→ 対応なし・不等分散(Welch検定)でp値を返す(最も汎用的)
使用例(対応あり・両側検定)
=T.TEST(A2:A11,B2:B11,2,1)
→ 前後比較・ペアデータなど対応のある場合に使用する
迷った場合は第4引数を「3」(Welch検定)にするのが最も安全な選択です。
Welch検定は等分散・不等分散のどちらにも適用できる汎用性の高い方法として広く推奨されています。
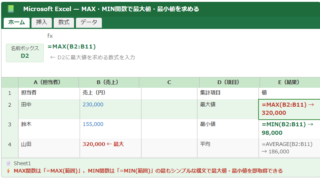
以下のイメージ図は、T.TEST関数を使った対応なし・両側・Welch検定の計算結果と、複数パターンの比較を示しています。
Microsoft Excel — T.TEST関数の各パターン比較(オートフィル活用)
数式
データ
fx
=T.TEST($A$2:$A$11,$B$2:$B$11,2,C2)
← C列の検定種類を参照してオートフィル
T.DIST関数でt値からp値を計算する方法
t統計量(t値)と自由度がすでにわかっている場合は、T.DIST関数を使ってp値を直接計算できます。
他のソフトウェアや手計算で求めたt値をエクセルでp値に変換したい場面で役立ちます。
T.DIST関数でt値からp値を計算する書式
=T.DIST(x, 自由度, 分布の形式)
分布の形式 → TRUE(累積分布関数)またはFALSE(確率密度関数)
両側検定のp値を求める場合
=T.DIST.2T(ABS(t値), 自由度)
例 t値が-2.35、自由度が18の場合
=T.DIST.2T(ABS(-2.35),18) → 0.0308(両側p値)
片側検定のp値(左側)を求める場合
=T.DIST(-2.35,18,TRUE) → 0.0154
両側検定のp値を求めたい場合はT.DIST.2T関数を使うのが最もシンプルです。
ABS関数でt値の絶対値を取ることで、t値が負であっても正しくp値が計算されます。
分析ツールを使ってt検定の詳細結果とp値を一括出力する
エクセルの「データ分析」(分析ツール)を使えば、t値・自由度・p値・t境界値などを一覧表として一括出力できます。
分析ツールが表示されていない場合は「ファイル」→「オプション」→「アドイン」→「分析ツール」にチェックを入れることで有効化できます。
分析ツールでt検定を実行する手順
「データ」タブ →「データ分析」→ 一覧からt検定の種類を選択する
「t検定 一対の標本による平均の検定」→ 対応のあるt検定
「t検定 等分散を仮定した2標本による検定」→ 対応なし・等分散
「t検定 分散が等しくないと仮定した2標本による検定」→ Welch検定
各フィールドに変数の範囲・仮説平均との差・α値・出力先を入力 → OK
→ t統計量・自由度・P(T<=t) 両側・t 境界値 両側などが自動出力される
分析ツールの出力結果にある「P(T<=t) 両側」の値がt検定のp値(両側)です。
NORM.S.DIST・CHISQ.TEST関数を使ったz検定・カイ二乗検定のp値の求め方
続いては、t検定以外のよく使われる統計検定のp値をエクセルで求める方法を確認していきます。
z検定・カイ二乗検定はそれぞれ異なる用途で使われる重要な検定です。
NORM.S.DIST関数を使ったz検定のp値の計算方法
z検定は、サンプルサイズが大きい場合(一般にn≥30)や母分散が既知の場合に2群の平均差を検定する際に使われます。
エクセルでは、z値を計算してからNORM.S.DIST関数でp値に変換します。
z検定のp値を求める計算手順
① z値を計算する
z = (標本平均 – 母平均) / (母標準偏差 / SQRT(n))
エクセル数式 → =(AVERAGE(A2:A31)-70)/(15/SQRT(COUNT(A2:A31)))
② NORM.S.DIST関数でp値を求める
片側p値 → =1-NORM.S.DIST(ABS(z値),TRUE)
両側p値 → =2*(1-NORM.S.DIST(ABS(z値),TRUE))
例 z値が1.96の場合
=2*(1-NORM.S.DIST(ABS(1.96),TRUE)) → 0.0500(両側p値)
NORM.S.DIST関数の第2引数を「TRUE」にすることで累積分布関数の値が返され、「1からその値を引く」ことで上側確率(片側p値)が得られます。
両側検定では片側p値を2倍することが必要な点を覚えておきましょう。
CHISQ.TEST関数でカイ二乗検定のp値を求める方法
カイ二乗検定は、クロス集計表(度数分布表)を使って2つのカテゴリ変数に関連があるかどうかを検定する方法です。
CHISQ.TEST関数は観測値と期待値の範囲を指定するだけでカイ二乗検定のp値を返してくれます。
CHISQ.TEST関数の書式と使用例
=CHISQ.TEST(実測値範囲, 期待値範囲)
実測値範囲 → 観測されたデータのクロス集計表(例 A2:C3)
期待値範囲 → 独立性を仮定した場合の期待度数の表(例 E2:G3)
期待度数の計算方法(各セルの期待値)
= (行の合計 × 列の合計) / 総合計
例 A2(行1合計×列1合計÷全体合計)→ =(E5*H2)/H5 のように計算する
使用例
=CHISQ.TEST(A2:C3,E2:G3) → カイ二乗検定のp値を返す
CHISQ.TEST関数は観測値範囲と期待値範囲の行数・列数が一致していないとエラーになるため、両方の範囲サイズを揃えることが必須条件です。
p値が0.05未満であれば「2つのカテゴリ変数は独立していない(関連がある)」と判断できます。
p値を求めるための検定の選び方まとめ
どの検定を使うべきかを素早く判断できるよう、検定の選び方を整理しておきましょう。
| 比較したいもの | 使う検定 | エクセルの関数 |
|---|---|---|
| 2群の平均(対応なし) | t検定(Welch) | T.TEST(,,2,3) |
| 2群の平均(対応あり) | 対応ありt検定 | T.TEST(,,2,1) |
| 2群の分散の等質性 | F検定 | F.TEST(配列1,配列2) |
| 大標本の平均(母分散既知) | z検定 | NORM.S.DIST関数でz値から計算 |
| カテゴリデータの関連性 | カイ二乗検定 | CHISQ.TEST(実測値,期待値) |
| 3群以上の平均比較 | 一元配置ANOVA | 分析ツール「一元配置分散分析」 |
この表を参照することで、自分が行いたい比較に対して正しい検定とエクセル関数を選ぶことができます。
p値の計算結果を整理して報告書・論文用の表にまとめる方法
続いては、エクセルで求めたp値を見やすく整理して報告書や論文に使える表として仕上げる方法を確認していきます。
p値を適切に提示することは、分析の透明性と再現性を高めるうえで非常に重要です。
検定結果を一覧表として整理するエクセルのレイアウト
複数の検定結果をまとめる場合、標準的な統計結果の表形式を使うことで読み手に伝わりやすくなります。
統計検定結果の標準的な表形式の例
比較項目 / 群A平均±SD / 群B平均±SD / t値 / 自由度 / p値 / 判定
エクセルで平均±SDを表示する数式の例
=ROUND(AVERAGE(A2:A11),1)&”±”&ROUND(STDEV.S(A2:A11),1)
→ 例「52.3±4.2」のような形式で表示される
p値を小数点3桁で表示する書式
=TEXT(E2,”0.000″)
→ 「0.031」のように3桁で統一表示できる
p値が0.001未満の場合の表記
=IF(E2<0.001,”<0.001″,TEXT(E2,”0.000″))
→ 極めて小さいp値は「<0.001」と表記するのが慣習
統計結果の表ではp値は小数点以下3桁(例「p=0.031」)で記載し、0.001未満の場合は「p<0.001」と表記するのが一般的な書き方です。
p値だけでなく効果量も合わせて報告する重要性
近年の統計学では、p値だけで結果を判断することへの批判が高まっています。
サンプルサイズが非常に大きい場合は、実質的に意味のない小さな差でもp値が0.001未満になることがあるためです。
そのため、p値と合わせて効果量(Cohen’s dやη²など)を報告することが推奨されています。
2群のCohen’s dはエクセルで以下のように計算できます。
Cohen’s d(効果量)をエクセルで計算する数式
Cohen’s d = (群Aの平均 – 群Bの平均) / 合算標準偏差
エクセル数式の例
=(AVERAGE(A2:A11)-AVERAGE(B2:B11))/SQRT((STDEV.S(A2:A11)^2+STDEV.S(B2:B11)^2)/2)
効果量の目安(Cohen, 1988)
d < 0.2 → 効果が小さい(small)
0.2 ≤ d < 0.5 → 効果が中程度(medium)
d ≥ 0.8 → 効果が大きい(large)
p値が有意であってもCohen’s dが小さい(0.2未満)場合は、統計的には有意でも実用上の意味は限定的である可能性があります。
IF関数を使ってp値の判定を自動化する実用的なテクニック
複数の検定結果を一覧で管理する場合、IF関数を使ってp値の判定を自動化しておくと非常に便利です。
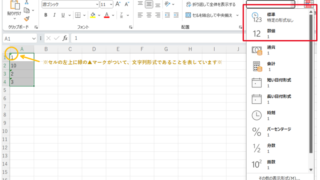
以下のイメージ図は、複数検定のp値一覧表に判定列を設けて自動判定している様子を示しています。
Microsoft Excel — p値判定の自動化(IF関数による星印表示)
数式
データ
fx
=IF(C2<0.001,”***”,IF(C2<0.01,”**”,IF(C2<0.05,”*”,”ns”)))
このようにIF関数とp値を組み合わせておくことで、データを更新するたびに判定が自動的に切り替わる管理表が完成します。
複数の比較を一括管理したい研究・調査の場面で非常に役立ちます。
まとめ エクセルでp値の出し方(計算式・見方も・0になる・t検定・統計検定での使い方)
この記事では、エクセルでp値を求める方法(p値の出し方・計算式・統計検定での使い方)について、p値の基本概念から各検定に対応した関数の使い方・結果の整理と報告方法まで幅広く解説しました。
エクセルでp値を求める基本はT.TEST関数で、対応あり・なし・等分散・不等分散(Welch)を第4引数(1・2・3)で指定して使い分けます。
z検定にはNORM.S.DIST関数、カイ二乗検定にはCHISQ.TEST関数、分散の等質性確認にはF.TEST関数を使うことで、さまざまな統計検定のp値をエクセル単体で計算できます。
p値は有意水準(0.05)と比較して判断し、IF関数で星印表記を自動化することで複数の検定結果を効率よく管理できます。
p値とともに効果量(Cohen’s dなど)も報告することで、より誠実で信頼性の高い統計分析の報告が実現できます。
今回の内容を参考に、エクセルでの統計検定とp値の計算をよりスムーズに進めていただけますと幸いです。